What if you could let an AI run overnight and wake up to a better trading strategy than you started with?
That’s basically what Andrej Karpathy built with autoresearch — a framework where AI agents modify training code, run experiments, evaluate results, and iterate. You go to sleep, you wake up to improved models and detailed logs
i took that idea and pointed it at trading
The seed
It starts with a dumb strategy. Twenty lines of JavaScript. Compare recent prices to older prices, check if volume is up, enter with a fixed size, exit at fixed PnL thresholds
Generation 0 fitness: 0.00. One single trade. Basically useless
From there the LLM takes over
How evolution works
Each generation runs three parallel mutations with different roles:
Exploit — tight mutation of the current best. Low temperature, conservative changes. “make this 5% better”
Explore — mutation from a random member of the top-5 pool. Higher temperature, wilder swings. “what if we tried something different?”
Crossover/Genesis — either merges two parents into something new, or every 5 generations generates a completely fresh strategy from scratch. “forget everything, start over”
All three run concurrently. Each candidate gets compiled via new Function(), backtested against real 1-minute BTC candle data, and scored on a multi-objective fitness function balancing Sharpe ratio, profit factor, win rate, trade count, drawdown, and raw returns
Winner survives. Rest gets discarded. Repeat
The fitness function
This is where it gets interesting. You can’t just optimize for returns — you get strategies that bet the farm on one lucky trade. Can’t just optimize for win rate either — you get strategies that never trade
fitness = sharpe * 0.25 + log(profitFactor) * 0.2 + winRate * 0.15
+ min(nTrades/50, 1) * 0.1 + totalReturn * 0.1
+ max(0, 1 + maxDrawdown) * 0.15 + (totalReturn > 0 ? 0.1 : 0)
Less than 10 trades? Fitness is zero. Got liquidated? Fitness is -10
This forces the LLM to find strategies that trade enough to be meaningful, don’t blow up, and actually make money risk-adjusted
Self-repair
LLMs don’t always write valid JavaScript. When a generated strategy fails to compile, a second LLM call at low temperature (0.3) tries to fix the syntax error. Only if repair also fails does the candidate score zero
Pretty important. Without auto-repair, roughly 15-20% of generations would be wasted on syntax errors
The coach
Every 10 generations a meta-LLM call reads the entire evolution log — every generation, every fitness score, every rationale — and produces coaching advice
“Mean-reversion with RSI has been tried 14 times. Only 3 were kept. Stop iterating on RSI-only strategies”
“The best improvements came from adding volatility-based position sizing. Double down on that”
“You’ve been stuck for 8 generations. The current paradigm is exhausted. Try something structurally different”
This reflection gets injected into the next batch of mutation prompts. It’s like having a research advisor who actually reads your lab notebook
Plateau escape
The system tracks consecutive failures. After 8 discards in a row, all three candidates switch to radically different approaches. After 16 it accepts a lateral move — a strategy within 70% of the current best — just to unstick the search
There’s also a paradigm scoreboard tracking which approaches (mean-reversion, momentum, RSI, trend-following) have been tried and how many were kept vs discarded. Prevents the LLM from endlessly recycling dead-end ideas
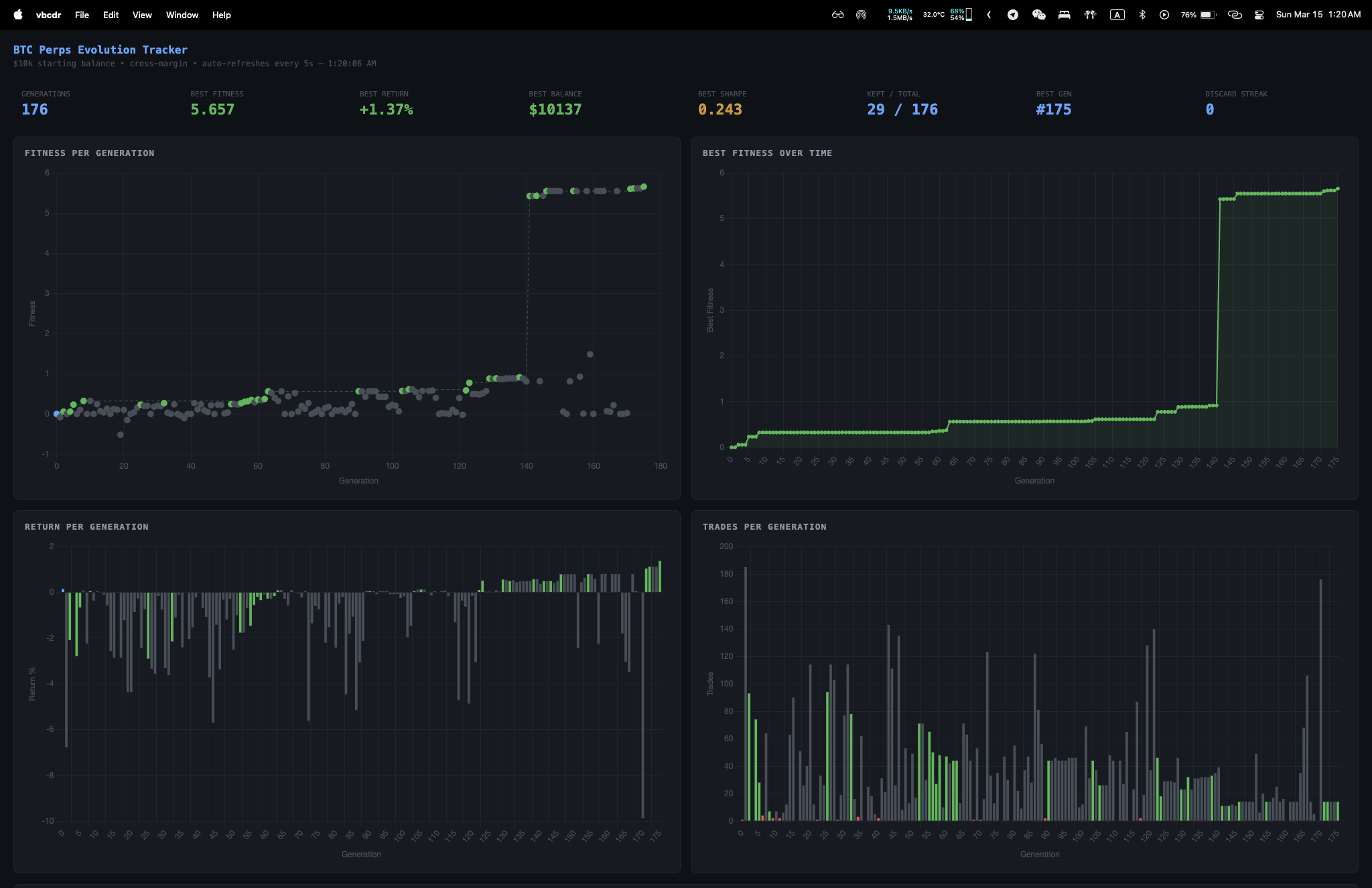
176 generations later
The whole thing ran for about 2 hours. 176 generations, 29 kept out of 176 total. Best strategy hit gen 175 with a fitness of 5.657, turning $10k into $10,137 with a 100% win rate and a best Sharpe of 0.243
What emerged was a ~200-line function with:
- Dual-period RSI (7 and 21) filters
- ATR-based volatility scaling at two timeframes
- MACD with EMA trend confirmation
- Bollinger Band squeeze detection
- CCI momentum confirmation
- Four-tier entry logic (primary, extreme, momentum, squeeze)
- Conviction-based position sizing
- ATR-based stops with profit-aware trailing
- Partial position reduction at 3x ATR gain
- Time-based exit at 50 candles
No human wrote this. It evolved from a 20-line seed through 176 generations of LLM-driven mutation, selection, and recombination
Here’s the full evolved strategy — gen 175, fitness 5.657:
function strategy(ctx) {
const candles = ctx.candles;
const n = candles.length;
if (n < 50) return { action: 'hold' };
const closes = candles.map(c => c.close);
const price = ctx.price;
function calcRSI(data, period) {
let gains = 0, losses = 0;
const start = data.length - period - 1;
for (let i = start + 1; i < data.length; i++) {
const diff = data[i] - data[i - 1];
if (diff > 0) gains += diff;
else losses -= diff;
}
const avgGain = gains / period;
const avgLoss = losses / period || 0.0001;
return 100 - 100 / (1 + avgGain / avgLoss);
}
function calcATR(candles, period) {
let sum = 0;
for (let i = candles.length - period; i < candles.length; i++) {
const prev = candles[i - 1] ? candles[i - 1].close : candles[i].open;
sum += Math.max(candles[i].high - candles[i].low,
Math.abs(candles[i].high - prev),
Math.abs(candles[i].low - prev));
}
return sum / period;
}
function calcEMA(data, period) {
const k = 2 / (period + 1);
let val = data[data.length - period];
for (let i = data.length - period + 1; i < data.length; i++) {
val = data[i] * k + val * (1 - k);
}
return val;
}
function calcBB(data, period, mult) {
const slice = data.slice(-period);
const mean = slice.reduce((a, b) => a + b, 0) / period;
const variance = slice.reduce((a, b) => a + (b - mean) ** 2, 0) / period;
const std = Math.sqrt(variance);
const width = (2 * mult * std) / mean;
const slicePrev = data.slice(-period - 1, -1);
const meanPrev = slicePrev.reduce((a, b) => a + b, 0) / period;
const variancePrev = slicePrev.reduce((a, b) => a + (b - meanPrev) ** 2, 0) / period;
const stdPrev = Math.sqrt(variancePrev);
const widthPrev = (2 * mult * stdPrev) / meanPrev;
return { upper: mean + mult * std, lower: mean - mult * std, mean, std, width, widthPrev };
}
function calcDonchian(candles, period) {
const slice = candles.slice(-period);
const high = Math.max(...slice.map(c => c.high));
const low = Math.min(...slice.map(c => c.low));
return { high, low, mid: (high + low) / 2 };
}
function calcCCI(candles, period) {
const slice = candles.slice(-period);
const typicals = slice.map(c => (c.high + c.low + c.close) / 3);
const mean = typicals.reduce((a, b) => a + b, 0) / period;
const meanDev = typicals.reduce((a, b) => a + Math.abs(b - mean), 0) / period || 0.0001;
const lastTypical = typicals[typicals.length - 1];
return (lastTypical - mean) / (0.015 * meanDev);
}
function calcBBWidthAvg(data, period, mult, lookback) {
let widthSum = 0;
for (let j = 0; j < lookback; j++) {
const slice = data.slice(-(period + j + 1), data.length - j);
const mean = slice.reduce((a, b) => a + b, 0) / period;
const variance = slice.reduce((a, b) => a + (b - mean) ** 2, 0) / period;
const std = Math.sqrt(variance);
widthSum += (2 * mult * std) / mean;
}
return widthSum / lookback;
}
const rsi7 = calcRSI(closes, 7);
const rsi21 = calcRSI(closes.slice(-35), 21);
const atr14 = calcATR(candles, 14);
const atr7 = calcATR(candles, 7);
const ema21 = calcEMA(closes, 21);
const ema50 = calcEMA(closes, 50);
const ema12 = calcEMA(closes, 12);
const ema26 = calcEMA(closes, 26);
const macd = ema12 - ema26;
const don20 = calcDonchian(candles, 20);
const bb20 = calcBB(closes, 20, 2.0);
const cci14 = calcCCI(candles, 14);
const trendUp = ema21 > ema50;
const trendDown = ema21 < ema50;
const atrPct = atr14 / price;
const slMultiplier = 2.0;
const slDist = atr14 * slMultiplier;
const volRatio = atr7 / atr14;
const volScale = volRatio > 1.3 ? 0.6 : volRatio < 0.8 ? 1.2 : 1.0;
const donRange = don20.high - don20.low || 1;
const donPos = (price - don20.low) / donRange;
const bbAbsFloor = 0.005;
const bbExpanding = bb20.width > bb20.widthPrev && bb20.width > bbAbsFloor;
const bbWidthAvg35 = calcBBWidthAvg(closes, 20, 2.0, 35);
const bbWasSqueezed = bb20.widthPrev < bbWidthAvg35 * 0.80;
const bbNowExpanding = bb20.width > bb20.widthPrev && bb20.width > bbAbsFloor;
const bbSqueezeBreakout = bbWasSqueezed && bbNowExpanding;
const macdThreshold = atr14 * 0.1;
const macdFloorStrict = -macdThreshold * 0.5;
const pos = ctx.position;
const gainPerUnitLong = pos.side === 'long' ? price - pos.avgEntry : 0;
const gainPerUnitShort = pos.side === 'short' ? pos.avgEntry - price : 0;
const partialReduceDone = gainPerUnitLong > atr14 * 4.0 || gainPerUnitShort > atr14 * 4.0;
let candlesHeld = 0;
if (pos.side !== 'flat' && pos.avgEntry > 0) {
let minDist = Infinity;
let entryIdx = n - 1;
for (let i = n - 1; i >= Math.max(0, n - 50); i--) {
const dist = Math.abs(candles[i].close - pos.avgEntry);
if (dist < minDist) { minDist = dist; entryIdx = i; }
}
candlesHeld = n - 1 - entryIdx;
}
if (pos.side === 'flat') {
const nearBBLower = price <= bb20.lower * 1.008;
const longPrimary = rsi7 < 30 && rsi21 < 55 && !trendDown
&& donPos < 0.45 && bbExpanding && nearBBLower
&& cci14 < -80 && macd > macdFloorStrict;
const longExtreme = rsi7 < 22 && rsi21 < 60 && donPos < 0.40
&& bbExpanding && nearBBLower
&& cci14 < -100 && macd > macdFloorStrict;
const longSqueeze = bbSqueezeBreakout && rsi7 < 28 && rsi21 < 55
&& cci14 < -90 && donPos < 0.45 && !trendDown
&& macd > macdFloorStrict;
if (longPrimary || longExtreme || longSqueeze) {
const conviction = longExtreme ? Math.max(0.7, (22 - rsi7) / 22) :
longSqueeze ? 0.65 :
Math.max(0.6, (30 - rsi7) / 30);
const baseSize = Math.min(
ctx.equity * 0.02 / (atrPct * slMultiplier),
ctx.equity * 0.85
);
const amountUsd = Math.min(
baseSize * conviction * volScale,
ctx.equity * 0.95
);
const sl = price - slDist;
const tpMult = trendUp ? 12.0 : 10.0;
const tp = price + atr14 * tpMult;
return { action: 'long', amountUsd, stopLoss: sl, takeProfit: tp };
}
const nearBBUpper = price >= bb20.upper * 0.992;
if (rsi7 > 68 && rsi21 > 45 && trendDown && donPos > 0.55
&& bbExpanding && nearBBUpper && cci14 > 80
&& macd < macdThreshold) {
const conviction = Math.max(0.5, (rsi7 - 68) / 32);
const baseSize = Math.min(
ctx.equity * 0.02 / (atrPct * slMultiplier),
ctx.equity * 0.85
);
const amountUsd = Math.min(
baseSize * conviction * volScale,
ctx.equity * 0.95
);
const sl = price + slDist;
const tp = price - atr14 * 10.0;
return { action: 'short', amountUsd, stopLoss: sl, takeProfit: tp };
}
} else if (pos.side === 'long') {
if (candlesHeld > 50 && pos.pnl / ctx.balance < 0.02)
return { action: 'close' };
const recentHigh = Math.max(...candles.slice(-25).map(c => c.high));
const inProfit = pos.pnl > 0;
const trailMult = partialReduceDone ? 1.0 : (inProfit ? 1.5 : 2.0);
const trailStop = recentHigh - atr14 * trailMult;
const gainPerUnit = price - pos.avgEntry;
if (gainPerUnit > atr14 * 4.0 && pos.sizeUsd > 100)
return { action: 'reduce', amountUsd: pos.sizeUsd * 0.5 };
if (inProfit && price < trailStop && trailStop > pos.avgEntry)
return { action: 'close' };
if (rsi7 > 72 || (trendDown && rsi7 > 50))
return { action: 'close' };
if (pos.pnl / ctx.balance < -0.02)
return { action: 'close' };
} else if (pos.side === 'short') {
if (candlesHeld > 50 && pos.pnl / ctx.balance < 0.02)
return { action: 'close' };
const recentLow = Math.min(...candles.slice(-25).map(c => c.low));
const inProfit = pos.pnl > 0;
const trailMult = partialReduceDone ? 1.0 : (inProfit ? 1.5 : 2.0);
const trailStop = recentLow + atr14 * trailMult;
const gainPerUnit = pos.avgEntry - price;
if (gainPerUnit > atr14 * 4.0 && pos.sizeUsd > 100)
return { action: 'reduce', amountUsd: pos.sizeUsd * 0.5 };
if (inProfit && price > trailStop && trailStop < pos.avgEntry)
return { action: 'close' };
if (rsi7 < 28 || (trendUp && rsi7 < 50))
return { action: 'close' };
if (pos.pnl / ctx.balance < -0.02)
return { action: 'close' };
}
return { action: 'hold' };
}
This started as 20 lines. The LLM added every indicator, every filter, every exit rule through iterative evolution
Cross-asset validation
On shutdown (Ctrl+C) the system tests the best strategy on held-out data and validates against ETH and SOL to check for overfitting. If a strategy only works on BTC training data it’s probably curve-fitted noise
The research pipeline
Alongside evolution, a separate agent searches YouTube for trading strategy videos, extracts the indicator rules, writes Python backtests, runs them, and saves results. Human-designed strategies from YouTube get evaluated with the same rigor as the evolved ones
Most of them score “mediocre” or “poor”
The autoresearch connection
Karpathy’s autoresearch uses a beautifully simple structure: one fixed data prep file (human-protected), one modifiable training script (agent-editable), and one markdown instruction file (human-crafted). The agent runs 5-minute experiments, measures a single metric (validation bits-per-byte), and iterates. About 100 experiments overnight
The evolving trader follows the same philosophy. The backtest engine is fixed. The strategy code is the single modifiable artifact. The evolution loop is the instruction layer. And the fitness function is the single metric driving selection
The key insight from autoresearch: you don’t program Python files anymore — you program markdown files that tell agents what to optimize. The agents write the code. You write the intent
What i learned
LLMs are surprisingly good mutation operators. They understand code structure, trading concepts, and can make meaningful modifications rather than random perturbations. Traditional genetic programming would need thousands of generations for what this achieves in dozens
Diversity matters more than exploitation. The parallel exploit/explore/genesis structure was essential. Pure exploitation gets stuck fast. The genesis mutations — completely fresh strategies every 5 generations — produced some of the biggest fitness jumps
The coaching loop is underrated. Without reflection the LLM keeps trying variations of the same failed approach. The coach provides the strategic memory that individual mutation calls lack
Fitness function design is everything. The multi-objective formula went through several iterations. Early versions over-weighted returns and produced strategies that traded once for a lucky profit. The final version forces a balanced approach
Is this the future of trading?
Honestly i don’t know. A fitness of 5.657 on training data with 14 trades and 100% win rate is suspicious — that’s likely overfitting to specific market conditions. Cross-asset validation helps, but real edge in markets is elusive
What i do know is the approach — using LLMs as intelligent mutation operators inside an evolutionary loop — is powerful beyond trading. It works for any domain where you can define a fitness function and evaluate candidates programmatically
Karpathy is optimizing language models. i’m optimizing trading strategies. Someone else could optimize game-playing agents, compiler flags, or drug molecule designs
The pattern is the same: define the search space, define the metric, let the agent explore overnight
As i write this the fitness is still climbing. Maybe i’ll let it run overnight and see what it finds by morning
Sleep well